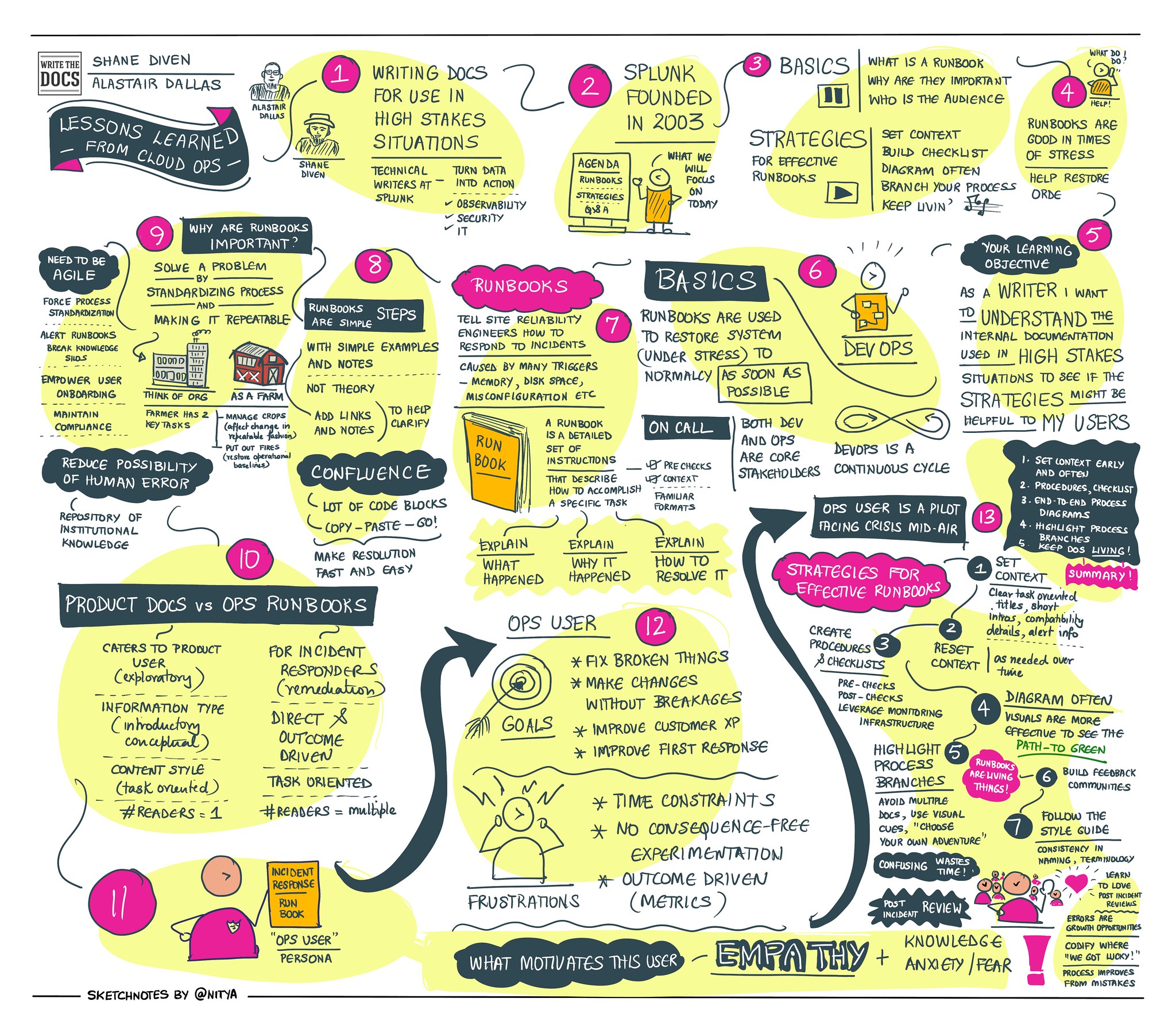
Lessons Learned from Cloud Ops: Writing Docs for High-Stakes Situations¶
Sketchnote
Description
Runbooks written for DevOps organizations offer an unusual set of writing challenges--time is of the essence for the reader and, often, performance is monitored.
At Splunk, we use runbooks to prescribe our response to incidents and to codify standard operating procedures. When an incident occurs, the goal is to restore operations as quickly as possible. For standard procedures, the goal is to affect change with no impact to the customer experience. In either case, the runbook must be useful–concise, complete, authoritative, and inclusive of escalation paths and other solutions if the first approach doesn’t work. Typical components of a Splunk runbook include:
- Workflow diagram
- Pre-Checks - Guided investigation; what is the sit-rep?
- Execution
- Post-Checks - How do we prove that the system is back to a healthy state?
- Labels to assist Confluence search, especially including synonyms
No matter what kind of writing you do, we think you’ll find the world of runbooks useful. Our reader’s goals may be different, but the strategies we use to write clearly and with urgency leave nothing to chance–and your readers may benefit from this approach, too. In this talk, you can learn:
- How we abbreviate information to speed up intake when time counts.
- How docs can work with teams to reinforce onboarding, expected behaviors, and additional training.
- How documentation can help DevOps blur the distinction between developers and operations teams.
- How to tighten feedback loops and plan for continuous improvement.
- Conference: Write the Docs Portland
- Year: 2022



